为 karakeep 爬虫配置 cookie 以绕过反爬虫机制
刷微博时看到有人介绍了自己的学习工作流,提到了一个名为 karakeep 的书签收藏软件。自己用 Docker 部署后发现确实好用,但是撞上反爬虫机制严重的网站就什么都爬不到了。查找后发现 karakeep 支持给爬虫设置 cookie,这样就能以正常用户身份去爬取数据。再经过一番努力后终于配置成功。这里附上教程,以供他人参考。
绕过反爬机制的方法
karakeep 撞上反爬虫机制严重的网站就是这样的效果(以百度贴吧为例)。
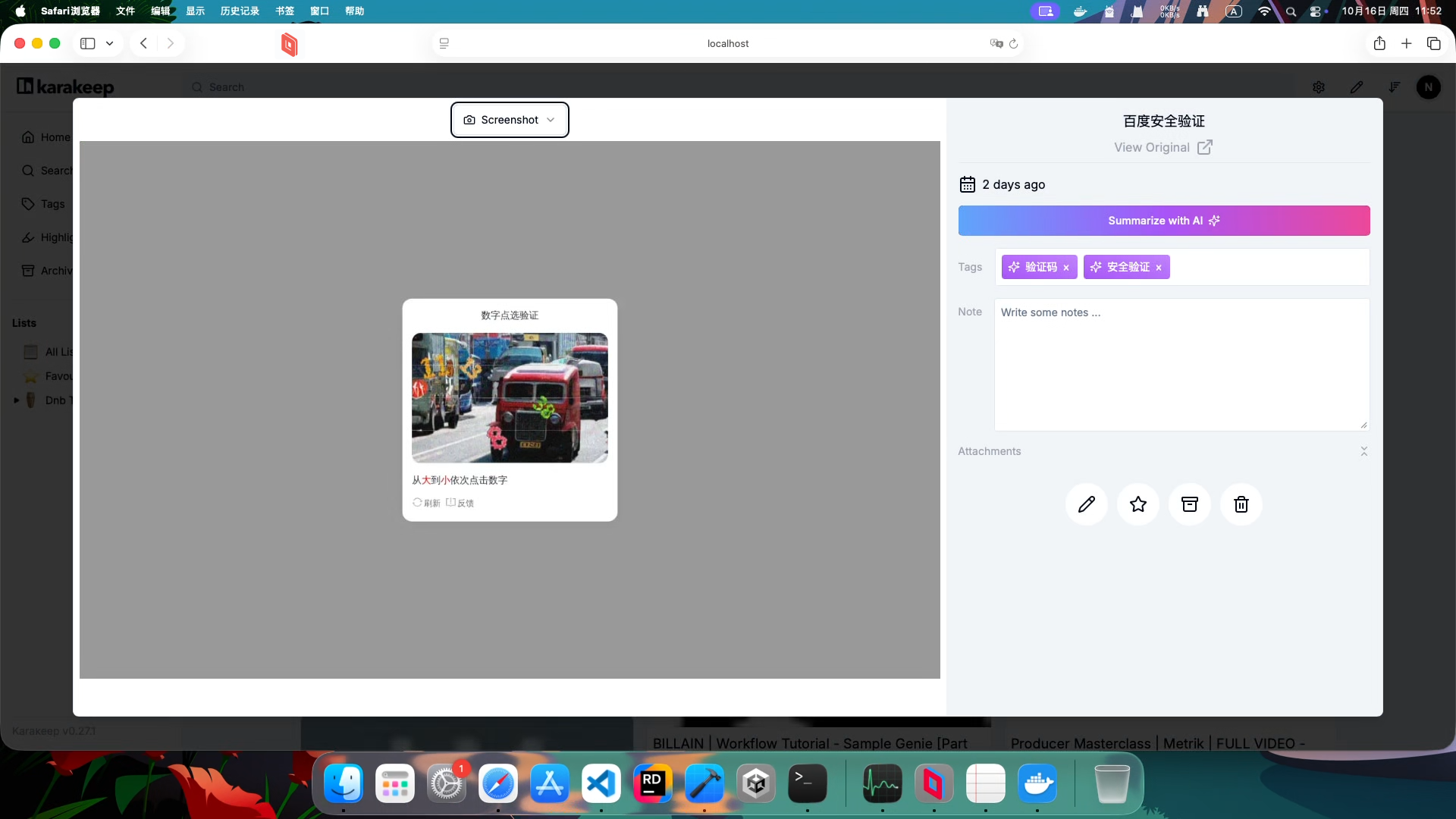
但 karakeep(旧名 Hoarder)作为一个发布已久的软件,肯定会想到这点。
我在文档里找了下。果不其然,在 Configuration | Karakeep Docs 的Crawler Configs 一节,官方给出了 BROWSER_COOKIE_PATH 参数,描述说:
BROWSER_COOKIE_PATH specifies the path to a JSON file containing cookies to be loaded into the browser context for crawling.
The JSON file must be an array of cookie objects, each with:
- name: The cookie name (required).
- value: The cookie value (required).
- Optional fields: domain, path, expires, httpOnly, secure, sameSite (values: “Strict”, “Lax”, or “None”).
Example JSON file:
2
3
4
5
6
7
8
9
10
11
12
{
"name": "session",
"value": "xxx",
"domain": ".example.com",
"path": "/",
"expires": 1735689600,
"httpOnly": true,
"secure": true,
"sameSite": "Lax"
}
]
只要配好这个文件,爬虫就能装成正常用户去访问了。现在知道要做什么了,开整!
创建并在 Docker 中配置 cookie 文件路径
首先我们要创建一个 json 作为 cookie 配置文件。我选择在跟 .env 同级的目录下创建了 browse-cookie-path.json。目录结构长这样:
1 | karakeep-app/ |
作为一个刚接触 Docker 两周的新手,最开始我以为建好后直接设置为文件路径即可。但 Docker 疯狂报 no such file or directory, open './browser-cookie-path.json' 时,我才被 Claude 老师告知:由于我的 karakeep 部署在 Docker 上,而容器无法直接访问宿主机内的文件,所以要将文件挂载到 volume 上。
修改 docker-compose.yml,挂上 cookie 文件:
1 | services: |
然后在 .env 文件里指定这个文件的路径,注意是 Docker 路径:
1 | BROWSER_COOKIE_PATH="/data/browser-cookie-path.json" |
这样就配好 cookie 文件的路径了。
获取 cookie
Cookie 来源好找。直接从浏览器里拿自己账号的 cookie 就行。然而,虽然官方文档说得很轻巧:“构造好 cookie 传给 crawler”,但百度这种大网站存取的 cookie 可是多如牛毛。自己构造 json 不知道要写到何时。
方法很简单:用浏览器插件导出就行。我用的是EditThisCookie。
装好后,来到贴吧,点击它,它就会列出这个网站用到的所有 cookie。点击“导出”,它就能自动生成符合格式的 json 并复制到你的剪贴板。
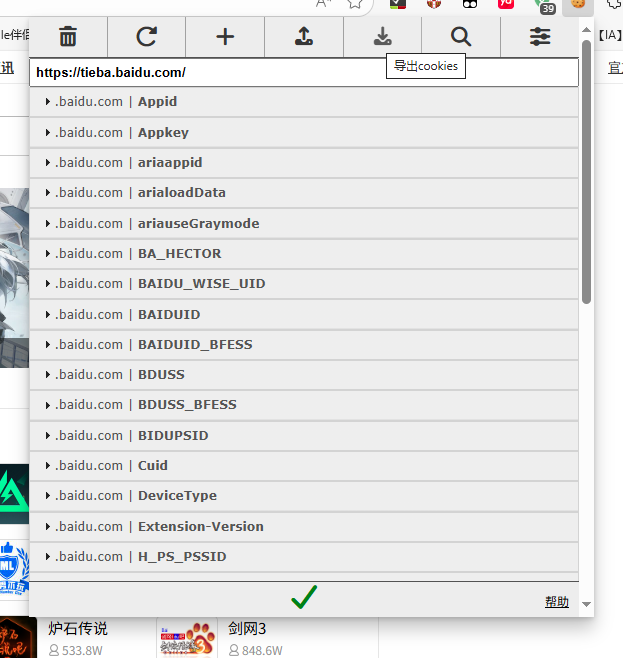
粘贴进 browse-cookie-path.json 里。
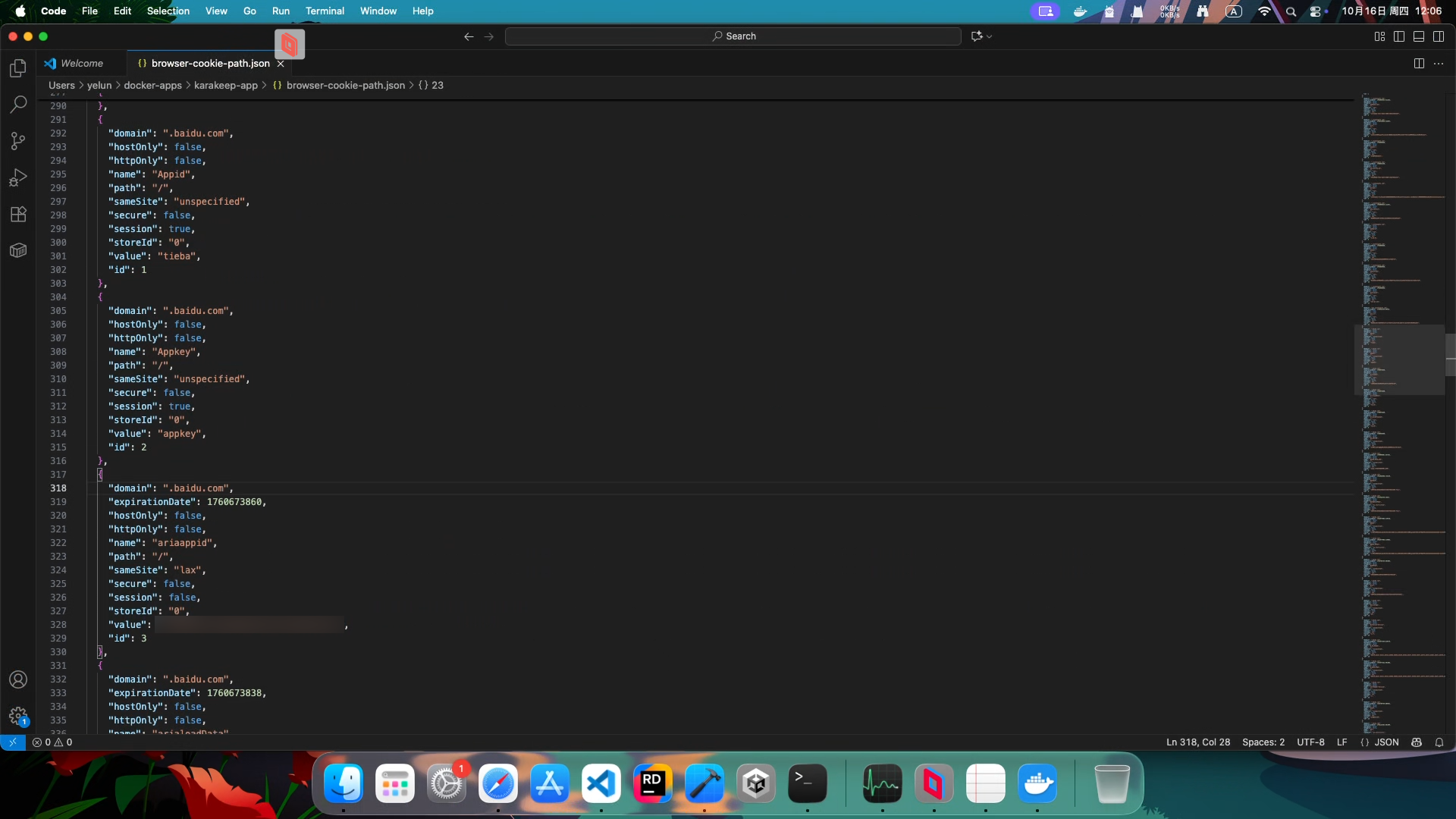
不过 EditThisCookie 对 sameSite 的标记与 karakeep 要求的值有点不一样。(我目前见到的)对应值大概如下所示:
| EditThisCookie 导出的值 | karakeep 使用的值 |
|---|---|
no_restriction |
None |
lax |
Lax |
unspecified |
Lax |
strict |
Strict |
查找替换一下就行。
配置好并保存后,重启一下 Docker:
1 | docker compose down && docker compose up -d |
一定要运行一次这个命令,不然修改过的 .env 文件不会生效。[^1]
现在重新拉取一下。虽然贴吧截图仍然没刷新,但现在就能正常拉取到贴吧的数据了。
小红书的效果:
配置 cookie 前:
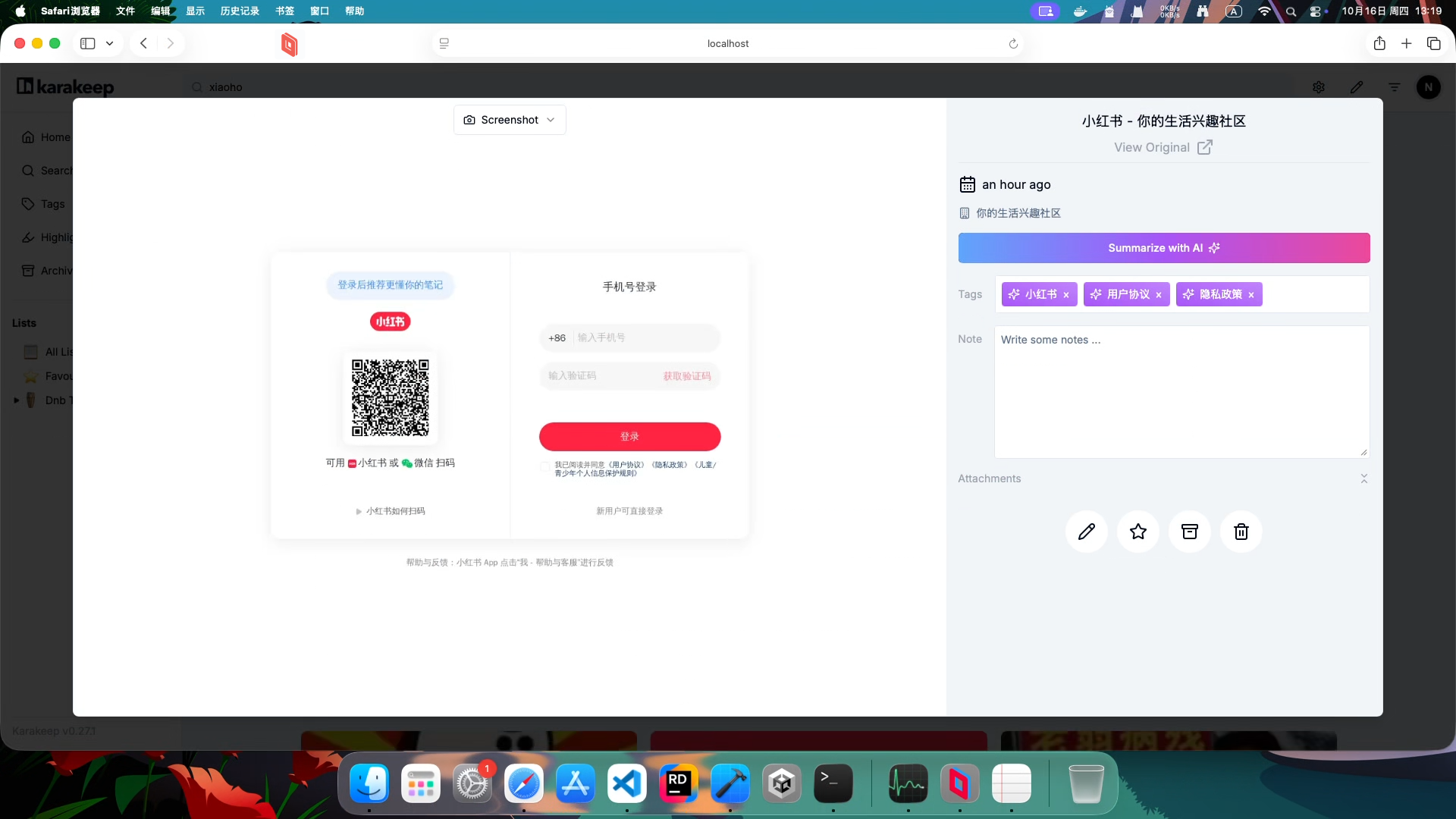
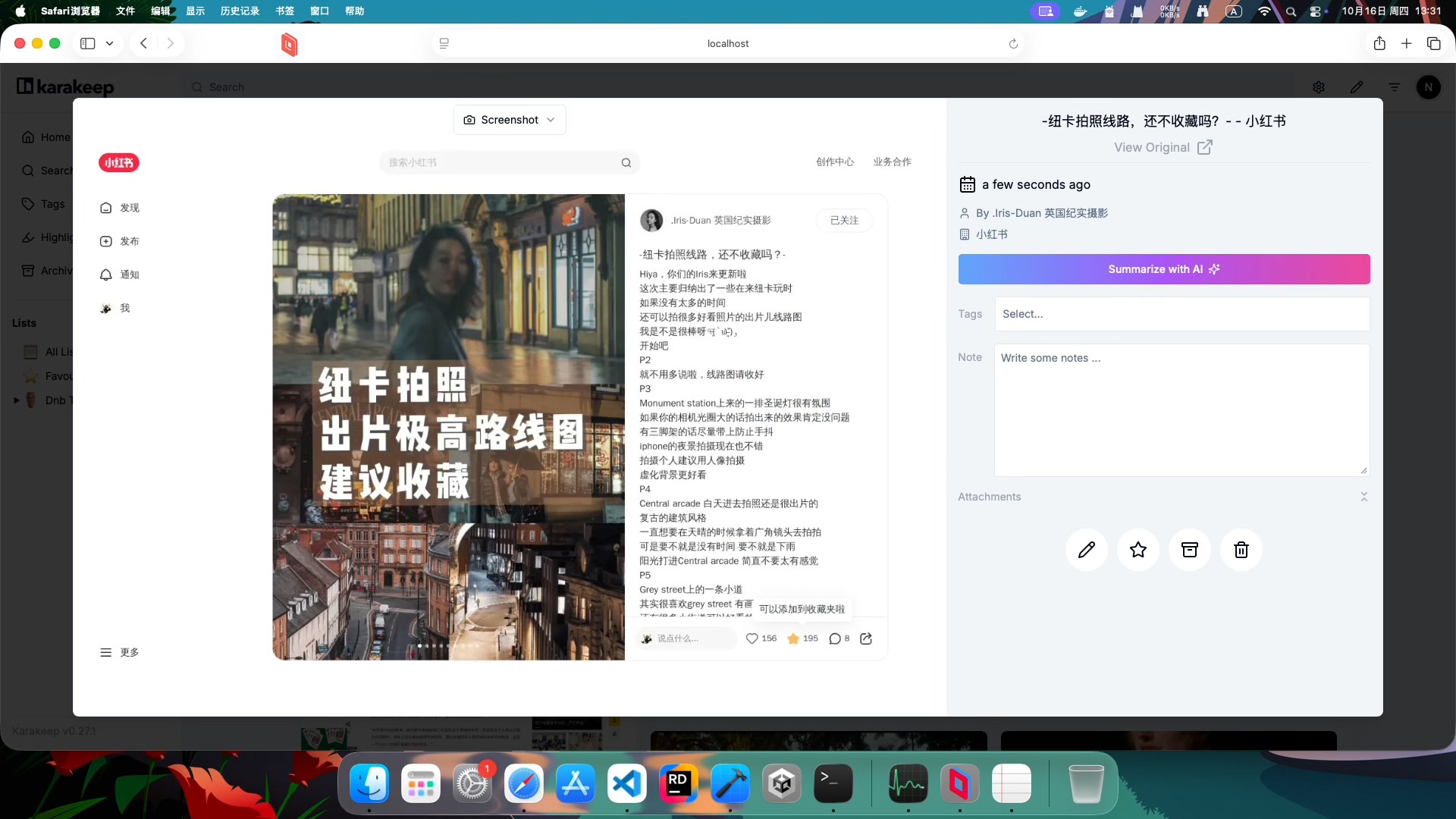
配置 cookie 后(截图、作者也全都刷新了,比贴吧效果好)(但是小红书没法拉取图片):
未来改进
这种 cookie 还是挺容易过期的。更新 cookie 应该也能用自动化脚本来做——不过那就是未来的事情了。
[^1]: # Hoarder 0.19 · RSS, AI Summarisation, Video Downloader and more